江苏东大金智信息系统公司,江苏 南京
摘要:跨摄像机下的行人重识别在公安刑侦、城市安保中有着很重要的实用价值。本文把行人检测与行人重识别算法相结合,搭建了行人重识别算法系统。通过测试发现,系统在相对理想条件下能达到很好的重识别效果。然而系统要能真正实用,还需要解决重识别判别条件设定以及克服光照、衣着等其他因素对行人重识别带来的影响等问题。文章最后对研究工作进行总结并指出了下一步研究方向。
行人重识别(Person re-identification,以下简称ReID)也称行人再识别,是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。广泛被认为是一个图像检索的子问题。给定一个监控行人图像,检索跨设备下的该行人图像。旨在弥补目前固定的摄像头的视觉局限,并可与行人检测/行人跟踪技术相结合,可广泛应用于智能视频监控、智能安保等领域。
由于不同摄像设备之间的差异,再加上摄像机的架设位置、拍摄视角以及拍摄距离各不相同,导致拍摄的行人大小尺寸、清晰度各不相同,人脸识别以及人脸特征在大部分情况下无法使用。另一方面光照强度的变化易导致同一行人在不同摄像机下的外观差异很大,通过颜色信息也很难匹配相同的行人。此外,由于行人属于非刚体目标,姿态和动作频繁发生变化,使得拍摄到的行人图像外观发生很大变化。
上述这些情况客观上为行人重识别带来巨大困难,使得行人重识别成为计算机视觉领域中一个既具有研究价值同时又极具挑战性的热门课题。迄今为止,尽管诸如旷视科技、阿里研究院等研究机构公开了其在公共图像数据集上的优秀成果,然而这些成果仍然停留实验室阶段。由于实际场景远比实验室场景复杂,现有算法在实际情况下的工作效果并不理想。
在实际工程中,摄像设备提供的影像中除了人还有物等其他背景,直接在带有背景的图像中进行行人重识别,不仅难度大、误判率高,而且带来巨大的计算复杂度。因此通常的办法是,首先从监控视频图像中将行人的检测出来,比如用一个矩形包围框把行人的位置坐标标识出来,然后对标识出的行人图片用ReID算法实现行人重识别。
上述两个步骤的目标函数不同 [1]。第一步行人检测关注的是行人之间的共性以及与周围环境的差别。第二步行人重识别关注的是行人之间的个性,要求描述不同身份的行人的特征向量距离尽可能大。因此在设计算法以及样本训练时,这两部分可以分开进行。
基于上述考虑,我们搭建了自己的行人重识别系统,系统包括两个核心模块,分别是行人检测模块和行人重识别模块。
对于行人检测模块,我们采用当前运用较广的目标检测算法YOLO[2]。YOLO在常规监控环境下对物体检测效果较好,不仅能很好地识别出“人”,而且相对其他算法具有检测快、计算复杂度低的优势。为此,在我们的系统中采用版本较新的开源算法YOLO V5[3]用于行人检测。YOLO V5的网络结构主要由主干网络Backbone、连接结构Neck、Head输出层组成,其中Backbone主要使用CSPdarknet+SPP 结构,Neck使用 PANet结,Head则使用YOLO V3 Head相似的结构。
在检测出普遍意义上的“行人”的基础上,需要识别出某个“人”,为此对于行人重识别模块,我们采用Kaiyangzhou 的deep-perosn-reid 算法[4]。deep-perosn-reid基于Pytorch,用于训练的图集来自于学术界最常用的几个公开数据集,包括Market1501, DukeMTMC-reID, CUHK01, MARS[5]。当前的神经网络是ResNet50, 损失函数为 Triplet。
算法实施包含如下几个步骤:
步骤1:运用行人检测算法取得查询(query)图集。
在本次工作中,首先用来做测试的是几个成对的视频,包括在马路行人过道的相对两侧,或者是在手扶电梯的楼上出口和楼下入口处,分别同时拍摄一个视频,例如得到视频 A.mp4 和视频 B.mp4。 使用YOLO,从A.mp4中按照一定的时间间隔,将所有识别为“person”的目标切成小块,以图片文件存储在query文件夹内。
步骤2:构建查询列表query_list。
在query文件夹中,手动选取包含同一个人的多张小块图,形成查询列表query_list, 使用deep-person-reid算法提供的特征提取器(FeatureExtractor)提取query_list中的特征向量。
步骤3:构建画廊列表gallery_list。
读取视频 B.mp4 ,仍旧使用YOLO从视频图像中将标记为“person”的目标区域保存到动态数组中,作为画廊列表gallery_list,使用FeatureExtractor 提取gallery_list的特征向量。
步骤4:计算query_list与gallery_list特征向量的欧氏(Euclidean)距离。计算欧氏距离的方法如下,假设query_list中某个行人图片P1的特征向量为(x1,x2,...,xn), gallery_list中某个行人图片P2的特征向量为(y1,y2,...,yn),则P1和P2之间的欧氏距离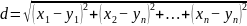 。
。
步骤5:根据欧氏距离进行排序,距离小的排在前面,距离越小代表两个图片中的行人相似率越高。
步骤6:根据预先设定的阈值,判断目标区域内是不是query中需要查找的人。
以上算法过程所达到的目标为:从视频A.mp4中选择几个行人形成待查询列表,然后在视频B.mp4中查找是否有待查询列表中的行人。
下图为系统测试结果。可以看出把YOLO 与deep-person-reid结合使用可以得到比较理想的行人重识别效果。

图1 行人重识别实验结果
尽管算法得到较好的实验结果,但应用于实际工程仍存在一定的距离,主要问题有2个:
如何找到一个普适的特征向量欧氏距离的判断阈值。
同一人背面与正面的衣着特征差有可能很大。
对于问题1,如果阈值过大,即判断依据太宽松,则会把不同的人误判为同一个人,导致误判率高。如果阈值过小,即判断依据太苛刻,则即使是同一个人也无法被识别出来。
为此,在我们的工作中采用如下方法:
假设在query_list中有10张查询图,用测试视频取得的gallery分别与这10张图计算特征差值,可以得到一个平均值mean_distmat,一个最小值min_distmat。另外,对query_list里的10张查询图自身做特征差值计算,得到mean_distmat_qq,计算比值 ratio=mean_distmat/mean_distmat_qq。在我们的实验中我们采用的判断条件为 ratio<1.6 或 mean_distmat<350 或 min_distmat<300。在测试中可以调节3个参量的阈值以及与/或的组合。



a) 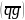 =705 b) =659 c) =425
=705 b) =659 c) =425
图2 特征差值过大的同一人图像
对于问题2,同一人的正面和背面,由于衣着、光照等影响,计算出的特征向量的欧氏差值会过大。图2显示了3组对比,a, b, c)的欧氏差值分别为 705,659,425。 图2 a)中的男子背面是一个背包,正面是敞开的露出黑色衬衫,只能通过“有个黑色拉杆箱”人工识别。 图2 b) 中穿棕色皮夹克的男子,在右边的图中由于光照原因丢失了大部分色彩信息,只能人工通过皮夹克的褶皱判断这是同一人。 图2 c) 中的女子,在右边图中也是由于光照原因丢失了大部分色彩信息,不过相对好于图2 b) 中的情况。 代表query_list的特征向量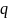 与gallery_list的特征向量
与gallery_list的特征向量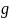 的欧氏距离。
的欧氏距离。
目前已经完成的工作有以下:
成功将行人检测与行人重识别结合,在同一软件环境下能同时运行YOLO和deep-person-reid。
使用Market1501, DukeMTMC-reID, CUHK01, MARS混合的训练集得到权重文件,从而能用特征提取器(FeatureExtractor)提取图像信息,用以做比较。
用多个以上成对的视频做验证,可以得到较好的重识别/人物跟踪效果。
目前学术界流行的重识别训练集中以侧面像为主,图像从清晰的到模糊的都有。在未来的工作中,可以考虑针对特定的工程要求和摄像条件,形成自己的重识别训练集,同时可以将以上几个训练集内相似的图包含在自己搜集的训练集中,这样可以提高针对性。否则差异太大的图同时存在在训练集中,会使损失函数难以收敛,降低效率。
另外,需要做更多的测试,增加场景类型,寻找一个之前提到的普适的特征向量欧氏距离的判断阈值与规则。
下一步工作包括:
搭建能既能运行 行人检测(Pedestrian Detection) 又能运行行人重识别 (Pedestrian Re-ID) 的软件环境, 可以不局限于YOLO 和 deep-person-reid,从而与当前完成的效果做比较。
根据实际工程要求和摄像条件,形成自己的训练集,同时挑选现有训练集中类似的图,放到新的训练集中。
增加测试场景,包括不同的光照条件,拍摄角度,寻找普适的重识别判断规则。
继续研究前沿重识别算法,测试比较不同的神经元网络。
参考资料
[1] 一些想法:关于行人检测与重识别,知乎 https://zhuanlan.zhihu.com/p/39282286
[2] 目标检测|YOLO原理与实现,https://pjreddie.com/darknet/yolo/
[3] YOLO V5,https://github.com/ultralytics/yolov5
[4] Omni-Scale Feature Learning for Person Re-Identification, https://arxiv.org/pdf/1905.00953.pdf
[5] 行人重识别数据集汇总,https://www.cnblogs.com/lzhu/p/14313615.html

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



