山东协和学院 山东省济南市 250109
【摘要】通过图表寻找近、中红外光谱中不同药材的特征和差异性;利用Spss软件通过聚类分析进一步对药材种类和产地进行鉴别和分类;通过相关性分析、欧式距离,研究光谱与产地的相关联系。
一、问题背景
红外光谱技术[1]是运用化学领域的相关知识,在原有的光谱测量基础之上结合产生的一种新型技术。其原理主要是用红外光线捕捉原子不同的振动的状态和相关的吸收频率实现分析和检测,这种技术的优点在于:简单、方便、分辨率高等。
二、问题处理
将药材按照种类和产地划分,以便对其进行相关研究,分类的方法采用聚类分析,对多条样本数据进行聚类,划分出规律或频率强度较为相似的为一类,以下即为分类过程:
1、不同种类药材特征和差异性分析
将数据按照从大到小的规律排列,按吸光度数据大小分为三组。利用Excel作折线图,通过初步的排序、作图、分析得出三种不同类型的药材中红外光谱曲线图,具体情况如图1:
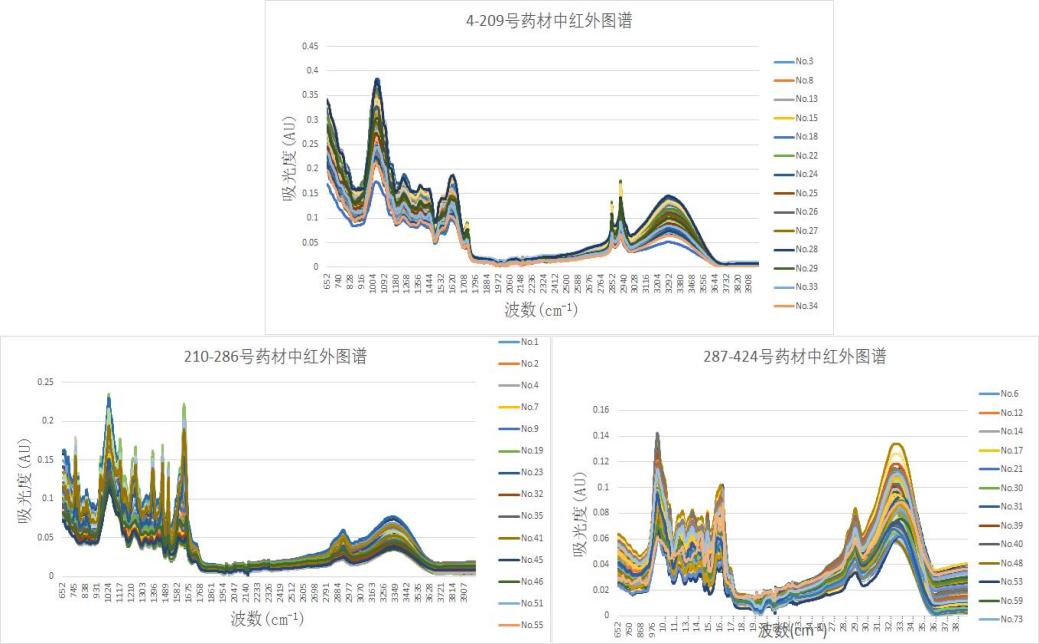
图1 不同分组的药材光谱图
据图1分析,不同的中药材的中红外光谱中的波形具有较大的差异,但是它们积极吸光的现象都集中出现在某一波段,根据图像特点和差异性分析,三段数据给出的图像主要差距在2400 cm-1—3300 cm-1波段,有一组在此波段吸光最激烈,其他几段在不同的波段表现并无太大差异。
2、用K-均值聚类分析法对药材进行分类
对附件1中的数据进行挖掘,根据图2展示的各组图像的特点,初步预测该数据大致可以分为三类。现利用SPSS软件,对附件1中的数据采用K-均值聚类分析法进行聚类分析,进一步进行检验,重复进行多次聚类分析,发现该数据包含不止三类药材,所以重新进行预测,在经过多次检验后,最终确定该数据可以分为四大类药材分别命名A、B、C、D一共四类。具体分析过程如下:
(1)在样本中任意挑选一个作为开始的第一个聚类中心;
(2)根据选出的聚类中心开始计算样本与中心的直线距离,若样本离临近的聚类中心越远,则被选为下一个聚类中心的可能性就越大;最后,依据概率的大小选出下一个聚类中心;
(3)将第(2)步重复多次,直到选出了K个聚类中心。然后再挑选出初始点就可以进行K-均值聚类算法。
3. 聚类分析结果分析
通过采用K-means聚类分析法进行聚类分析,得出如下图2
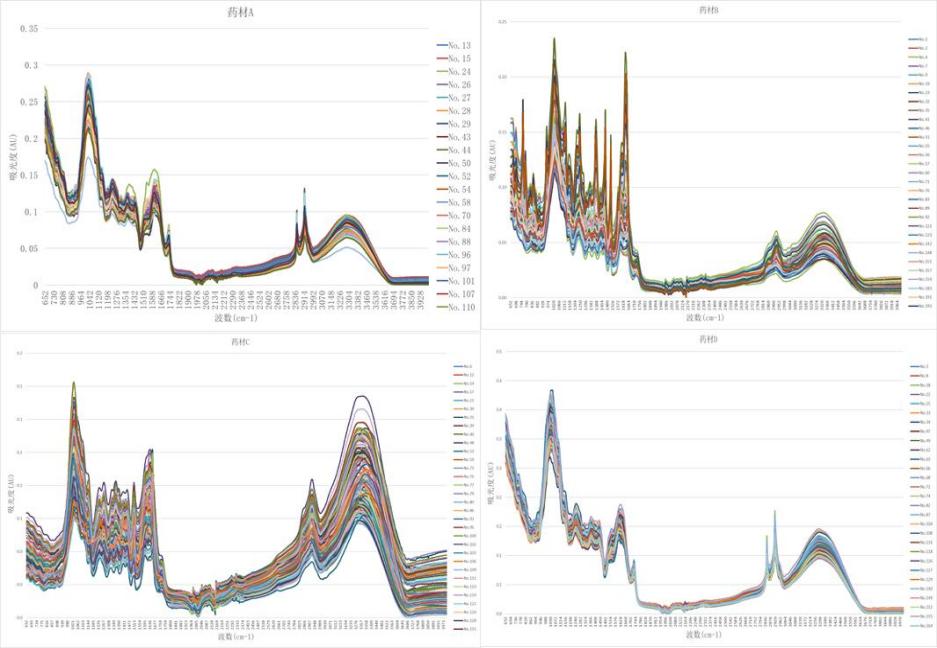
图2 数据聚类分析图
根据图2显示,A类药材中包含63个数据,具体特征为:该类药材在652 cm-1—964cm-1区间内吸光度下降明显,B类药材中包含66个数据,具体特征为:在882 cm-1—1158cm-1区间内吸光度大幅度上升。C类药材中包含134个数据,具体特征为:在939 cm-1—1185cm-1区间内吸光度大幅度上升。D类药材中包含83个数据,具体特征为:药材在652 cm-1—862cm-1区间内吸光度下降明显。
4、方法检验分析
采用K-均值聚类分析方法对数据进行鉴别分类,得出不同种类的中药材的中红外光谱中的波形具有很强的相似性,与通过对比发现,得到的结果基本一致,证明该方法在鉴别过程中,使用恰当。
5、同种药材不同产地的中红外光谱研究分析
按照产地分类进行排列,把相同产地的药材按产地分别进行分析。然后,选取相同产地的药材作图分析,以产地1为例,任意提取四种产地1的药材数据作图,具体特征如图3。

图3 相同产地药材光谱图
综上所述,同种产地的药材与不同产地的药材在吸光波段的变化上并无太大差异,基本趋于一致,不同点在于相同产地的同种药材在峰值吸光倍率方面差异较小,但不同产地的同种药材在峰值吸光倍率方面差异较大,结合题目给出信息推断,不同产地间由于无机元素的化学成分、有机物等存在差异,因此其原子在吸光度上表现不同。
6、 基于系统聚类算法的中药材产地的鉴别
利用Spss对数据进行系统聚类,得到聚类谱系图,同时得到聚合系数,利用肘部法则找到最优分类节点数K。
对聚合系数折线图进行分析可知,当类别数K为5时斜率骤变,折线的下降趋势趋缓,故可将类别数设定为5。在仅有中红外数据的情况下,所有产地的光谱比较接近,因此难以区分未知产地具体所属,所以通过聚类分析,先分析出一部分未知产地与已知产地相似度极高的类别,这部分类别误差较小。剩余数据误差较大,难以分析,只能使用相关系数寻找细微差别进行分类。
7、利用欧氏距离对药材产地进行鉴别
(1)欧氏距离:
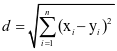 (1)
(1)
其中d为未知产地光谱与平均光谱吸收度值的距离,其中xi,yi 分别为未知产地光谱与平均光谱吸收度对应的数值,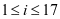 。
。
(2)近红外光谱的鉴别
利用欧氏距离对未知产地分别与每组产地的近红外光谱的数据平均值进行计算,计算结果最小的即为与未知数据最接近的产地。
三、参考文献
[1]刘沭华,张学工,张素琴.中药材产地的近红外光谱自动鉴别和特征谱段选择
[J].2005.50(04):393-398.
[2]朱乐.基于近红外和中红外光谱的细菌分类与浓度检测研究[D].2020.6:17-38.
2

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



