1. 南京中软卓训 信息技术有限公司,江苏,南京, 211106 2. 金陵科技学院软件工程学院,江苏,南京, 211106
摘要:本文针对海量网络舆情信息的分析和处理问题,提出了从网络舆情信息采集、分析、处理的全流程解决方案,设计和实现了基于前后端的舆情分析系统,后端采用SSM框架,前端采用微信小程序,结合NLP算法,实现网络舆情摘要的自动生成,为用户提供简洁而有价值的信息。
关键词:网络舆情;摘要生成;NLP;SSM;微信小程序
1.问题背景
网络舆情是对公众产生一定影响的社会事件。在网络媒体中,人既是信息的浏览者,又是信息的发布者。日常生活中,有各种传播信息的平台,比如微博、微信和QQ等,使用这些在线平台,为我们生活中中信息的沟通提供了各种便利。信息传播的表现形式有多重,比如视频、声音、文本或者上述结合等,大多数还是以超文本方式比较多,面对大量的互联网数据,如要发掘一些有用信息,必须借助于网络舆情系统,对这些数据进一步挖掘和提炼。本文采用B/S模式,后端采用SSM(Spring+SpringMVC+Mybatis),前端采用微信小程序,自然语言处理NLP算法,设计和实现一个网络舆情分析系统。
根据上述问题背景,分析并总结系统的需求如下表所示。
表1.系统需求规格说明
序号 | 用户角色 | 功能点 | 描述 |
01 | 网民 | 识别实时热搜 | 识别当下关注度最高的实时热点,并对其进行舆情分析。 |
02 | 网民 | 舆情关键词生成 | 总结网络用户对于一个热点的评论使用最多的几类关键用词,依此形成摘要 |
03 | 数据统计人员 | 舆情倾向分析统计 | 用户一般会对于一个热点有自己的看法和见解,统计出一个热点的几大类普遍的说法以及对应的人数占比。 |
04 | 网络监察人员 | 敏感信息检测 | 检查网民对于实时热点有无过激言论以及透露个人信息等不当敏感言论 |
3.系统架构
系统架构如图1所示。
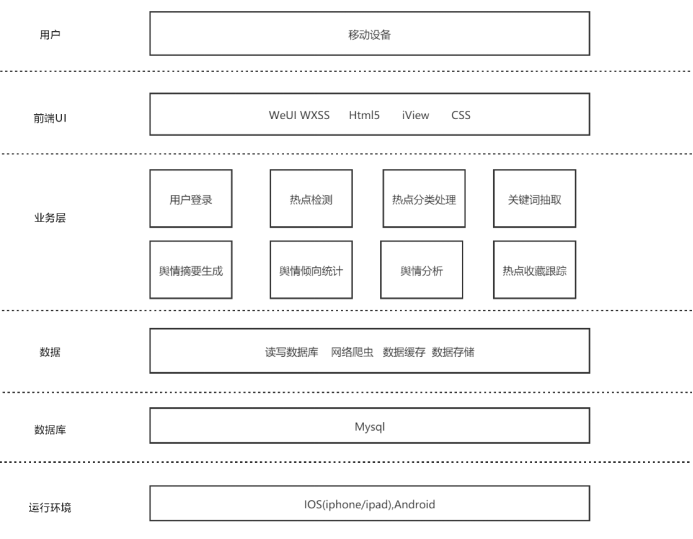
图1.系统架构
说明:
系统采用B/S结构,后端采用SSM(Spring+SpringMVC+MyBatis)框架,前端采用微信小程序,采用前后端分离交互模式。通过网络爬虫来爬取网上的评论信息。通过自然语音处理NLP算法对爬取的网上评论信息进行分析,并自动生成舆情摘要。
4.主要算法
defa():
#chromeOptions=webdriver.ChromeOptions()
##设置代理
#chromeOptions.add_argument("--proxy-server=http://117.88.5.185:3000")
#driver=webdriver.Chrome(chrome_options=chromeOptions)
driver=webdriver.Chrome(executable_path='./chromedriver')
driver.get('https://bbs.hupu.com/')
#连接数据库
conn=mysql.connector.connect(user='root',password='990303',host='localhost',port='3306',database='test',
use_unicode=True)
#获取游标
c=conn.cursor()
#模拟url
html=[]
foriinrange(1,5):
forjinrange(1,6):
s='//*[@id="container"]/p/p[2]/'+f'p[{i}]'+'/ul/'+f'li[{j}]'+'/span[1]/a/span'
#print(s)
html.append(s)
#设置主页,以便返回
homepage=driver.current_window_handle
#模拟点击链接,进入子页面
topic_id=1
comment_id=0
forkinrange(25):
driver.find_element_by_xpath(html[k]).click()
driver.implicitly_wait(10)
page=driver.window_handles
driver.switch_to.window(page[-1])
#time.sleep(0.2)
#获取标题
while1:
try:
title=driver.find_element_by_xpath('//*[@id="j_data"]').text
break
except:
pass
print(title)
#获取内容
while1:
try:
content=driver.find_element_by_xpath('//*[@id="tpc"]/p/p[2]/table[1]/tbody/tr/td/p[2]').text
#ifcontent=='视频无法播放,浏览器版本过低,请升级浏览器或者使用其他浏览器':
#content=''
break
except:
pass
print(content)
sql=f'''insertintoTopic(Topic_id,TopicName,TopicCon)values({topic_id},'{title}','{content}')'''
print(sql)
c.execute(sql)
conn.commit()
#获取评论
forminrange(1,41):
comment_id=comment_id+1
try:
comment=driver.find_element_by_xpath('/html/body/p[7]/p/p[1]/p[1]/p/form/p[2]/p/'+f'p[{m}]'+'/p[2]/table/tbody/tr/td/p').text
ifcomment=='':
break
#写入数据库
sql=f'''insertintoComment(Comment_id,Topic_id,Comment.`Comment_c`)values({comment_id},{topic_id},'{comment}')'''
print(sql)
c.execute(sql)
conn.commit()
exceptExceptionase:
print(e)
print("暂无更多评论")
break
topic_id=topic_id+1
driver.close()
driver.switch_to.window(homepage)
c.close()
conn.close()
实现截图:
(2)主要模块2:运用NLP对信息内容进行分析(关键字提取,分词摘要,情感分析),并将分析好的内容插入数据库。
A.对内容进行分析
fromtextrank4zhimportTextRank4Keyword,TextRank4Sentence
fromsnownlpimportSnowNLP
classAbstract():
#获取文章关键字,返回关键字列表
defkeyword(self,text):
word=TextRank4Keyword()
word.analyze(text,window=2,lower=True)
w_list=word.get_keywords(num=4,word_min_len=2)
returnw_list
实现截图:



正面评论中性评论负面评论
5.结语
本文针对海量网络舆情信息的分析和处理问题,提出了从网络舆情信息采集、分析、处理的全流程解决方案,设计和实现了基于前后端的应用系统,后端采用SSM框架,前端采用微信小程序,结合NLP算法,实现网络舆情摘要的自动生成,为用户提供简洁而有价值的信息。下一步的工作在于提高网络舆情摘要的正准确率。
参考文献
[1]黄晓斌,赵超.文本挖掘在网络舆情信息分析中的应用[J].情报科学,2009,27(01):94-99.
[2]杜昌顺,黄磊.分段卷积神经网络在文本情感分析中的应用[J].计算机工程与科学,2017,39(01):173-179.
[3]马梅,刘东苏,李慧.基于大数据的网络舆情分析系统模型研究[J].情报科学,2016,34(03):25-28+33.
[4]格桑多吉,乔少杰,韩楠,张小松,杨燕,元昌安,康健.基于Single-Pass的网络舆情热点发现算法[J].电子科技大学学报,2015,44(04):599-604.
[5]金鑫,谢斌,朱建明.基于复杂网络分析的微博网络舆情传播[J].吉林大学学报(工学版),2012,42(S1):271-275.
基金项目:
江苏省现代教育技术研究课题(课题编号:2018-R-63099)
金陵科技学院引进人才科研启动金(课题编号:jit-rcyj-201802)
广西自然科学基金(课题编号:2018GXNSFAA050046)

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



