天津农学院 天津 300384
[摘要]:
本文研究基于YOLOv3算法对奶牛个体的识别方法。伴随“物联网+现代农业”重大方针政策的推广,现代牧业的大规模涌现也成为了人们关注的焦点。现代牧业中奶牛的智能化养殖突显出智能化在牧业发展中所起到的关键的作用,许多大规模养殖奶牛的牧场,在奶牛达到一定数量后,奶牛数目的清点就成为了他们所要考虑解决的问题了,如果人工清点,则会耗费大量时间和人力,并且很容易出现误差,造成经济损失。计算机的深度学习算法可以代替人工计算,并且更精准的实现奶牛数目的统计。
[关键字]:奶牛个体识别;YOLOv3算法;深度学习
1、引言
当今人们生活水平不断的提高,对牛奶和肉类食品的需求也在不断的增加。随之增加的是大规模的牧场,已经不再是一个人养几头奶牛那么简单。而传统的奶牛个体识别是以人工观测为主,这种方式不再适用于大规模的牧场。继人工观测识别,还有人工机械识别和接触式电子识别。但随着人工智能与深度学习在诸多领域的兴起,深度学习的各种算法用于奶牛个体的识别将成为趋势。我们想研究YOLOv3算法在奶牛个体识别上的应用,来设计农场奶牛数目的统计和奶牛健康状态的判别系统。对比其它的深度学习算法,YOLOv3有更好的主干网络Darknet-53,该网络借用了ResNet网络的思想,在网络上中加入了残差模块,有利于解决深层次网络的梯度问题,每个残差模块有两个卷积层和一个shortcut connections,使结果精度更好。
2、检测算法
2.1、传统目标检测算法
级联分类器框架用于早期的传统目标检测算法,通过简单弱分类器拼装强分类器的过程,效果虽然很难达到人们的要求,但它让该类算法使得目标检测成为现实。主要流程见图2.1。在该类算法的基础上,学者们提出了HOG+SVM的分类算法[1]。主要过程见图2.2。该类算法在行人检测上具有很大的优势。
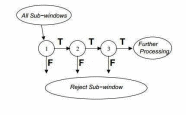
图2.1 特征拼装流程图

图2.2 HOG+SVM算法流程图
2.2、深度学习算法
随着传统目标检测算法的各种缺点被暴露出来,基于卷积神经网络的方法随之兴起。该算法对目标特征进行提取,减少了人工提取特征的不足。2014,Ross Girshick提出了基于卷积神经网络的R-CNN的目标检测模型[1],这类算法通过候选区域/窗,再加上深度学习分类,通过提取候选区域,并对相应区域进行以深度学习方法为主的分类方案。工作流程如下图2.3.
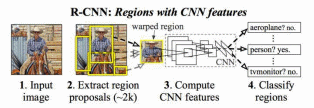
图2.3 R-CNN工作流程图
R-CNN被提出不久后,各种基于R-CNN的模型,如Fast R-CNN、Faster R-CNN、RFCN、Mask R-CNN相继出世。R-CNN家族的检出率相当高,但因为候选区生成非常耗时,催生了新的目标检测算法。
2.3、YOLOv3算法
YOLOv3算法顾名思义是YOLO算法的第3个版本,是YOLO算法经过3次更新迭代的产物。该算法的主要网络由Darknet-53来充当,而Darknet-53网络采用全卷积结构,在前向传播中,张量的尺寸变换是通过改变卷积的步长来实现的。YOLOv3的基本思想是特征提取网络从输入图像中提取特征来获得特定大小的特征图,然后看ground truth中的Object的中心坐标落在那个grid cell中,这个grid cell用来预测该object,最后通过RPN网络中每个grid cell预测一定数量的Bounding Box,这里YOLOv3是3×3个,这几个Bounding Box中只有和ground truth的IOU最大的才是用来预测Object的[1]。图2.4附上YOLOv3结构图。
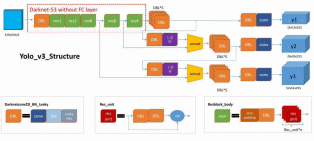
图2.4 YOLOv3结构图
3、模型构建
3.1、图片预处理
由于奶牛养殖场环境复杂、光照不均等,导致图像中包含噪声及边缘模糊等,需要去除图像中的噪声,并做图像增强等预处理,以提高有效信息占比,为后续目标检测、特征提取和个体识别等奠定良好的基础[3]。
3.2、网络输入
YOLOv3算法实现过程中有5次下采样,每次使用步长为2的卷积来进行下采样,所以网络的最大步幅为2^5 = 32,目标检测输入图像大小必须是32的整数倍数[3],通常的输入图像大小为:320 × 320,416 × 416,608 × 608 等。
3.3、边界框预测
将输入的图片压缩为416px×416px(px代表像素),我们将采集到的图片装换位Pascal VOC数据集格式,将一个图片分为若干个S×S的网格,进行网络训练。其中适合检测较大对象的有(116×90)、(156×198)、(373 ×326);适合检测中等大小对象的有(30×61)、(62×45)、(59×119);适合检测较小对象有(10×13)、(16×30)、(33×23)
[2] 。在每个网格内检查边界框和置信度,用T( x,y,w,h,C)来表示每个网格单元具体信息,x、y分别表示当前网格单元预测检测对象的置信度中心位置的横、纵坐标,w、h 分别表示外接矩形的宽度和高度,置信度C 则表示当前网格单元中是否包含奶牛目标及其预测准确性,通过阈值对预测结果进行取舍。假设图像的左上角为坐标原点,则预测的边界框可表示为
bx = f(x) + dx;by = f(y) + dy; bw = pwew; bh = pheh;
式中:bx、bw分别代表预测边界框中心点的横、纵坐标值;f(x)、f(y)分别代表预测边界框中心点与最近网格边缘在x、y 向的距离;dx、dy分别代表网格的横、纵坐标偏移量;bw、bh分别代表预测边界框的宽度和高度; pw、ph分别代表锚点框的宽度和高度。
位置边框采用logistic 预测目标对象的置信度。如果预测边界框与真实边界框重叠,并且预测结果优于所有其他边界,则该框的值为1,否则为0。
3.4、构建YOLOv3模型
网络的基本结构单元为卷积单元和残差单元:卷积单元:
conv2D->BatchNormalization->LeakyRelu
这部分卷积全部为3×3的卷积核大小
LeakyRelu: if(xi > =0) yo = xi; else yo = xi/a (a>1);
残差单元:
1×1卷积,n个filterBN,L_Relu,->3×3卷积,2×n个filter,BN,L_Relu->与input相加->线性激活函数 图2.5Darknet-53
Input:根据Darknet-53的网络进行输入。见图2.5。
O utput:总共6个卷积单元,23个残差单元,每个残差单元有2个卷积,因此6 + 23×2 = 53,darknet-53有53个卷积操作。
utput:总共6个卷积单元,23个残差单元,每个残差单元有2个卷积,因此6 + 23×2 = 53,darknet-53有53个卷积操作。
目标检测部分采用类似特征金字塔的方式,在网络中选取三层feature map 做为目标分类与定位的特征Tensor,在网络中选取了第26个卷积层(52,52,256),第43个卷积层(26,26,512)和第53层(13,13,512)。第53层的结果经过下图一系列的卷积变为(13,13,255)-> reshape (13,13,3,85);第43层的结果与53层卷积操作和up sampilng卷积之后的结果concat,经过下 图2.5
图一系列的卷积变为(26,26,85)-> reshap (26,26,3,85);第26层的结果与43和53层卷积操作和up sampilng(介绍上采样卷积)卷积之后的结果concat,经过一系列的卷积变为(52,52,85)-> reshape (52,52,3,85); 在数据集上统计最优的9个anchor,这个类似与Faster RCNN中RPN产生proposal 的时候9种尺度的anchor box ,只不过yolo-v3这里使用的在coco数据集上训练出来的特定比例,应该算是一组超参数。anchors = [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45],[59, 119], [116, 90], [156, 198], [373, 326]]。同时与anchors对应的还有9个Maskmasks = [[6, 7, 8], [3, 4, 5], [0, 1, 2]],Mask把anchors分成三组,在进行目标预测的时候,conv53对应的mask为6,7,8, 对用anchor的后三个;conv43对应的mask为3,4,5,对用anchor的中间三个; conv26层对应的mask为0,1,2,也就是说,在比较小的feature map上预测较大的目标,在比较大的feature map上预测小目标。针对3个卷积层的output,一共可以得出:((52×52) + (26×26) + 13×13)) × 3 = 10647 bounding boxes然而我们的图像中一般这么多的目标,需要进行与之筛选和NMS(非最大抑制)根据box_confidence和输入的阈值,去除小于阈值的框,非最大抑制(受IOU 参数的影响)是为了去除一个目标同时被多个框预测,保留其中概率最大的框最为目标框。
3.5、测试及验证结果
将Pascal VOC数据集分为训练集、测试集和验证集。将训练集放入网络进行训练,为了防止过拟合,多次进行网络训练。然后再用测试集和验证集进行测试和验证。
得到的置信度大多在0.8及以上,最高可以达到0.94,置信度超过0 5 认为识别正确,不高于0.5 认为识别错误。
4、结语
本文通过研究YOLOv3算,实现对奶牛个体的识别。通过深度学习的方法对奶牛的识别相比人肉眼检测的速度更快、准确度更高。不仅如此,更解放了不少的劳动力,对未来的奶牛生产有着跨时代的意义。
参考文献:
[1] 谭俊. 一个改进的YOLOv3目标识别算法研究[D].华中科技大学,2018.
[2] 王毅恒,许德章.基于YOLOv3算法的农场环境下奶牛目标识别[J].广东石油化工学院学报,2019,29(04):31-35.
[3]何东健,刘建敏,熊虹婷,芦忠忠.基于改进YOLO v3模型的挤奶奶牛个体识别方法[J].农业机械学报,2020,51(04):250-260.
[作者简介]
胡翔昊(1998—),男,河南信阳人,汉族,天津农学院在读本科生,专业方向:软件工程
通信作者:赵光煜(1973—),男,天津西青人,汉族,天津农学院教师,专业方向:大数据应用、人工智能
[基金项目]天津市互联网跨界融合创新科技重大专项(项目名称:基于物联网与大数据分析的畜禽精准化生产研发与应用,项目编号:18ZXRHNC00080);2019年度天津市大学生实践创新训练计划项目(项目名称:基于机器视觉的奶牛个体识别及清点系统的研发,项目编号:201910061039)。

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



