曲阜师范大学,山东 ·日照 276800
【摘要】随着图片所含带的信息量不断增多,能否有效对图像进行处理并提取出其中的重要信息是目前正在研究的热度问题之一。基于图片信息提取和加工的软件能够帮助人们完成这些任务,主要功能为:对于单一图片,能识别提取文字信息、表格和图标等,分别保存为对应的文件格式;对于批量图片,能批处理识别文字,保存到文档中。该软件的开发涉及OpenCV图像处理、文字检测和识别、PyQt5等相关知识,已实现基本功能,在识别率、信息提取精确度方面尚需不断深入研究。
Abstract:As the amount of information contained in pictures continues to increase, the ability to effectively process images and extract important information is one of the hot issues currently under study. The software based on image information extraction and processing can help people to complete these tasks. The main functions are: for a single picture, the extracted text information, tables and icons can be identified and saved as corresponding file formats; for batch pictures, batch identification can be recognized. Text, saved to the document. The development of the software involves OpenCV image processing, text detection and recognition, PyQt5 and other related knowledge. Basic functions have been realized, and further research is needed in terms of recognition rate and accuracy of information extraction.
【关键词】图片识别;信息提取;OpenCV图像处理;OCR;PyQt5
Key words:picture recognition; information extraction; OpenCV image processing; OCR; PyQt5
【基金项目】曲阜师范大学2018年校级大学生创新创业训练计划项目(2018A095)
1 引言
图片作为各类信息的载体之一,其在信息传播和交流中占有重要的地位。计算机能够帮助处理很多人工操作复杂的问题,因此使用计算机的处理能力有利于帮助减轻人员工作,加快工作效率。计算机视觉[1]的发展,将机器与图像处理融合得更加紧密。在计算机处理图片这一方面,各种技术发展层出不穷,如OpenCV图像处理技术[2],它轻量而且高效,提供了Python语言的接口,能实现图像处理和计算机视觉方面的很多通用算法。在文字识别方面,OCR(即光学字符识别)技术应用范围也越来越广,它能模拟人类视觉的智能对目标图像进行判断和识别,当下的 OCR 技术已经能较好的识别一般规整文档扫描件等。
对于电脑软件用户界面的设计,PyQt5是基于图形程序框架Qt5的Python语言实现,由一组Python模块构成,能设计出较为美观、交互性良好的GUI界面。
本软件是基于PC端的本地可执行文件,实用性较强,相对于一般常用的图片文字识别软件的功能,该软件较深层次地研究图片信息识别技术,既能够满足用户对图片信息加工提取的一般需求,如通用的文字识别、目标区域的检测和提取并保存,也能识别批量的图片文字;对长期需要这几项功能的用户来说,意义匪浅。
2 软件功能分析
2.1 功能分布
该软件主要分为四大功能,如图1所示,具体表述如下:
①通用文字识别:用户选择将要识别的单张图片,图片将显示在GUI界面,点击识别按钮,将在本界面的文本框显示识别结果,用户可直接保存识别的文字结果到Word文档中或者复制使用。另一方面,用户也可选择划出图片区域进行识别。
②批量图片识别:选择好将要识别的文件夹路径,点击识别即可,所有在文件夹下的图片将被统一处理到同一文档中。
③表格提取:用户选择含有表格的图片文件,点击识别将能直接保存成Excel形式的表格文件。
④局域图形提取:该功能旨在提取出图片中较为突出的形状或物体区域,如常见的图标。
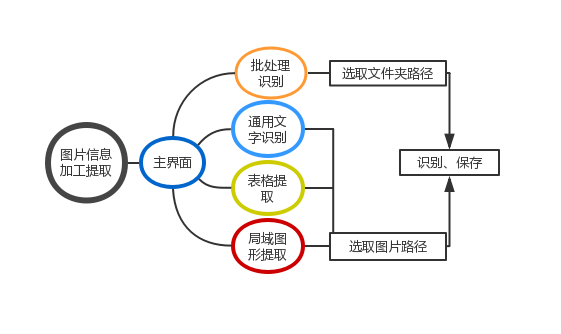
图1 功能分布图
2.2 技术分析
2.2.1 编程相关
①采用Python语言编写,Python版本为3.7;并引入版本号为4.1.0的OpenCV库,即cv2;
②编程环境为PyCharm,版本为JetBrains PyCharm 2018.3.1 x64;
③采用Qt Designer及PyQt5相关知识设计用户可视化界面。
2.2.2 具体功能技术
①基本图像处理
主要采用OpenCV处理图像的相关知识,主要是图片读写、图片缩放、灰度转换、图像二值化、图片切割等常用操作。
②文字检测
该软件采用版面分析法中的基于图像处理的目标图像轮廓提取法,其大体流程可以分为为图像预处理、图像边缘处理、图像轮廓提取几个部分。基于OpenCV图像处理工具包,其涉及的图像平滑、阈值分割、形态学处理、边缘检测、颜色空间等方法的实现,能有效检测到文字区域。
③文字识别
该软件考虑采用卷积神经网络(CRNN)训练文字集模型来识别文字[3]。CRNN文字识别的基本步骤为:第一,下载网络开源的文字集或者自己代码生成训练样本;第二,构建模型开始训练;第三,测试模型效果,保存模型;第四,在文字识别代码部分直接调用模型进行使用。
④目标区域提取
表格提取:第一,先用OpenCV图像处理将图片中的表格检测出来,用横向和竖向的细长的条去腐蚀膨胀可以得到横线和竖线,整合起来就能得到表格框架;第二,本软件采用在代码中调用百度AI接口的方式,将之前裁剪出来的表格图片直接识别,然后保存识别后的表格文件。
局域图形提取:主要采用OpenCV的轮廓检测和形态学处理方法,可较为准确地定位到比较突出的形状和物体,裁剪出来即可。
3 软件设计与实现
3.1 界面设计
①主窗口:包括四个选项卡,分别代表四个功能,进入软件的主界面默认为普通文字识别功能选项卡,如图2:

图2 主界面头部及其选项卡
其中,软件使用QMianWindow类创建主界面窗口,主窗口中含有一个菜单栏,接着包括四个tab选项卡。
②功能选项卡:包括通用(普通)文字识别、批处理识别、表格提取、局域图形提取四个选项卡,分别位于四个“tab”控件里,都主要包含用于显示图片或者文件夹路径的lineEdit控件、用于显示图片的label控件、用于显示识别结果的文本框控件textEdit控件,以及各个按钮。
3.2 各功能程序实现
由于各部分程序有功能类似的部分,故主要分成以下几个部分的程序实现:
3.2.1 读写图片文件/文件夹
①读取文件:调用QFileDialog类的getOpenFileName方法可打开一个读文件的对话框,用于选择文件,该方法可返回文件路径。
②读取文件夹:调用QFileDialog类的getExistingDirectory方法可打开读取文件夹的对话框,进行选择文件夹操作。
③保存文件:调用QFileDialog类的getSaveFileName方法打开保存文件的对话框。
3.2.2 文字检测
基于图像处理的目标图像轮廓提取能有效定位文字:
①图像预处理:采用OpenCV中的技术,cv2的cvtColor方法能将图片灰度化,也可以适当将图像缩放处理;
②图像边缘处理:Sobel 算子能实现边缘处理,cv2中的Sobel方法能得到形态学变换的预处理效果,接着调用threshold方法实现图像二值化;
③图像轮廓提取:借助形态学变换,cv2的getStructuringElement方法是设置膨胀和腐蚀操作的核函数,连续使用多次即可将文字区域划分出来;调用cv2的findContours方法可查找所有轮廓区域,对所有轮廓区域进行筛选得到最小区域即可把各小块的文字轮廓提取出来。
3.2.3 文字识别
采用卷积神经网络(CRNN)实现文字识别[5],获得图像样本后,进行如下操作:
①划分训练集和测试集,并单独存储为两个文本文件;把原始数据集转化为lmdb格式以方便后续的网络训练,方法是先读入图像和对应的文本标签,使用字典将该组合存储起来(cache),再利用lmdb包的put函数把字典(cache)存储的键值对写成lmdb格式存储。
②构建CRNN模型进行训练:采用Pytorch库[4],CRNN由CNN、RNN、CTC三部分架构组成;第一,CNN采取VGG16深度神经网络结构图[5],该部分引入BatchNormalization模块,能够加速模型收敛。第二,RNN部分使用了双向LSTM,隐藏层单元数为256,RNN层的输出维度将是(s,b,class_num),其中class_num为文字类别总数。第三,由于pytorch没有内置的CTC loss,故通过网络下载开源的CTC loss来完成损失函数部分的设计。
③测试训练模型:在文字识别部分载入训练好的模型,读入待测试的图片,转换成灰度图后送入网络,查看输出结果。
3.2.4 目标区域检测和提取
①表格识别提取
第一,读取图像并二值化,接着进行膨胀腐蚀等形态学操作,调用cv2的approxPolyDP方法来拟合表格的四边形,找轮廓使用cv2的findcontours方法,得到表格框架图片。
第二,使用百度API接口,主要方法是client.tableRecognitionAsync,直接识别表格及其内容,通过file_download方法保存到本地。
②局域图形提取
第一,使用cv2的cvtColor方法二值化图片;
第二,使用cv2的Gaussian_Blur方法进行图片高斯去噪;
第三,使用索比尔算子Sobel_gradient方法计算方向梯度,方便边缘处理;
第四,形态学处理,调用cv2的morphologyEx、erode、dilate等方法;
第五,图片裁剪,得到目标图形。
4 结语
该软件有良好的用户界面,整体功能较为完善,且各项功能操作简便易懂,文字识别率相对较高。
OpenCV图像处理功能强大,在软件程序设计中属于核心技术部分,贯穿着整个软件系统的图像处理操作。OpenCV与Python的结合,让整个程序更加协调、简洁,充分体现着OpenCV的轻量性和高效性,以及Python语言粘性的特点。
在图像处理上,可以考虑OpenCV和深度学习的不断结合,在文字检测、目标检测等功能实现方面,能构建出合适高效的训练模型,这需要设计人员在今后的学习、开发和测试中不断把握核心技术,更加注重细节以及程序的鲁棒性,从而进一步完善软件功能。
参考文献
[1]李玉玲.人工智能在计算机视觉及网络领域中的应用[J].电脑编程技巧与维护,2018,No.398(08):158-159+163.
[2]刘培军,马明栋,王得玉.基于OpenCV图像处理系统的开发与实现[J].计算机技术与发展,2019,29(03):133-137.
[3]丁小刚.BP神经网络与卷积神经网络在文字识别中的应用研究[D].华中科技大学,2014.
[4]高华照.基于深度卷积神经网络的图像识别算法研究[D].
[5]廖星宇.深度学习入门之PyTorch[M].北京:电子工业出版社,2017.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



